
· 8 min read
Design Patterns For Extensible Controllers — Part 1
Design Patterns For Extensible Controllers

This article is based on the presentation by Rafael Fernández López & Fabrizio Pandini titled Kubernetes is Your Platform: Design Patterns For Extensible Controllers. The purpose of this article is to bring some examples and go a bit more in depth on the conventions presented. Be sure to check out the presentation on YouTube. Some of the terms are different between this article and the presentation, this is made so we are closer to the terms defined by Kubebuilder/Operator-SDK.
Kubernetes Operators. There are not only increasing amount of existing solutions, with an increasingly mature and well documented Kubebuilder and Operator-SDK enables DevOps Engineers to potentially provide custom solutions for enterprise costumers too.
But what is a Kubernetes Operator anyway? While this article is definitely targeting people with some experience with Kubernetes extensions, let’s do a rundown anyway:
- Controller: A single reconcile loop, eg. The ReplicaSet controller.
- Manager/Operator: A component that runs one or more controllers, like the kube-controller-manager.
- Custom Resource: An instance of a Kubernetes type defined by using Custom Resource Definitions. A custom resource is formed by metadata, spec and status.
- Owner: Controller responsible for creating and deleting a resource. E.g. ReplicaSetController owns the Pod resources.
- Watch: The action of a controller that looks for resources under your control and other resources as well. E.g. ReplicaSetController watches ReplicaSet resources. As extending Kubernetes is becoming mainstream and the need to solve more complex problems in a cloud-native way increases, using a single controller easily becomes a limit.
This article will discuss reusable design patterns that are considered good practices in the field.
Orchestrate many controllers

A common way to deal with complex problems is to break these down into a set of tasks assigned to smaller controllers and resources. These controllers then can handle these tasks in a distributed way without a single controller ballooning in complexity.
We are going to look at three different ways on how to orchestrate different controllers and resources.
Controllers watching the same object
The simplest solution is often the best. At times when we want to attach certain behaviours to an existing resource, we can take a look at the following example:

We can deploy a secondary controller that watches for the same resource with the defined role of reconciling its finalizers or annotations. It’s worth noting that the practice of two controllers reconciling the same resource is generally frowned upon by both Kubebuilder and Operator-SDK. To avoid mayhem, our secondary controller has to have a very well defined role in the lifecycle of our resource so it does not have an adverse effect on the reconciliation process of the primary one. Like we said earlier, our goal is to break down a complex problem to a set of tasks, not complicate them further.
So what’s a good example for this? Garbage collection! It involves logic that happens just before we want to destroy the resource, so implementing it aside an existing controller should be no problem. Also we are quite lucky because Kubernetes already has a really nice feature for us to exploit: finalizers.

We’re going to use an existing controller-resource pair and add a brand new controller which watches for the same resource. The sole thing that we will do with this controller is attach a finalizer that nobody else handles and well… Handle it.
In our example the result is simple yet effective. When we kubectl delete our resource, our original controller does its magic, but this time around the resource doesn’t get immediately deleted by the api-server, it waits until the finalizer is removed from it.
Disclaimer: Our original controller needs to “respect” finalizers. This generally does not require extra work as controllers that do not handle finalizers generally don’t care for resources with a deletionTimestamp set.
Let’s look at the code.
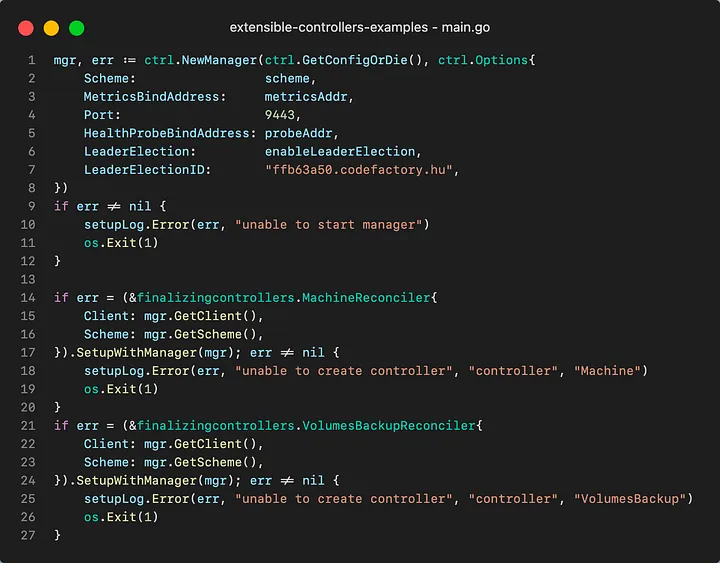
Our manager has two registered controllers an “original” MachineReconciler and our VolumeBackupReconciler which handles finalization.
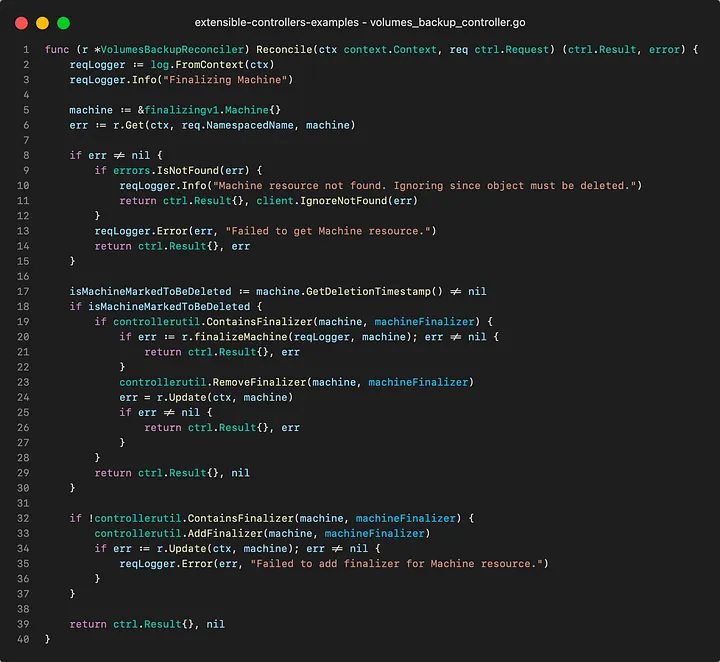
Our VolumeBackupReconcil reconcile cycle handles operations only regarding the finalizer. It adds it to resources that are not in deletion and removes it from resources that are, after running some associated logic.
Lessions learned
Use when
- You want to make progress when a precondition is met: e.g. Machine is deleted
Pros
- Responsibility is well defined: Each controller does one task.
- It is a battle tested pattern (e.g. garbage collector).
Cons
- Limited orchestration options, e.g. finalizers
- Behavioural dependencies between controllers is not well documented, they do not surface in the API.
Controllers watching related objects
What happens when finalizers and annotations are simply not enough? This is where our next solution comes into the picture.
If we want to completely detach ourselves our original resource, along with its limitations, we can take a look a the following pattern:

Here, rather than using finalizers or annotations as our platform for our extension, we create a completely new resource. This new resource is going to do the heavy-lifting for tasks that are while separate from our original resource, still needs to be done. This resource is going to have its own controller which handles it’s reconciliation and status.
In our example above, we created a very simple skeleton of what the Kubernetes Deployment and ReplicaSet controller does. As most of you probably know, Kubernetes Deployments don’t handle the lifecycle of their pods directly. They offload these responsibilities to ReplicaSets. The Deployments are only responsible for the lifecycle of these ReplicaSet resources while only taking into account their spec and status. Their inner workings are neither known nor relevant. As such the Deployment Controller watches for Deployment resources and tries to reconcile them by creating ReplicaSets.
When implementing our own controllers, this scenario gives us a lot more orchestration options because we are in full control of the lifecycle of a completely new resource along with its spec and status formats.
Let’s take a look at a hypotetical BasicDeployment and BasicReplicaSet resource:
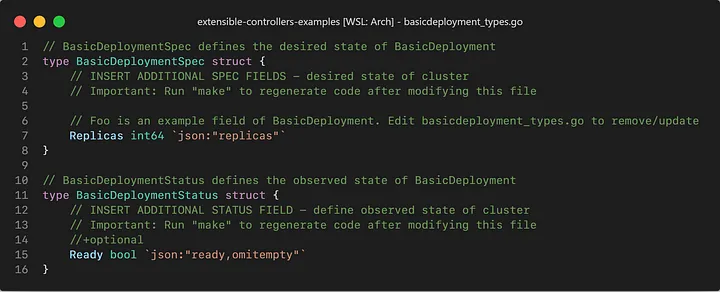
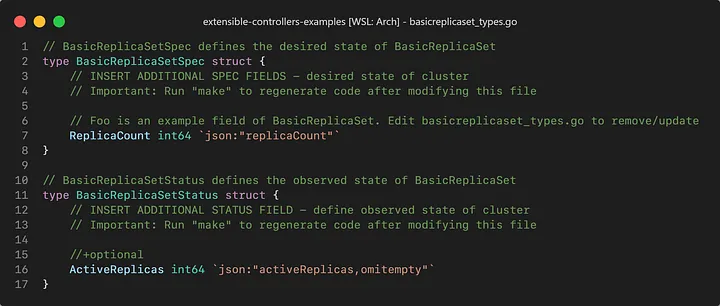
Both of our resources are rather simple. Our BasicDeployment only has a single specification, which is the desired number of replicas and it reports only a boolean status: Whether the deployment is ready or not. Our BasicReplicaSet isn’t too different either, it still has the desired number of replicas, but on its status, it reports back how many replicas are “Active”.
The job of our original BasicDeployment Controller becomes simple. It only needs to create the BasicReplicaSet with the given spec and wait until the active replicas match the desired amounts. It doesn’t need to know how the BasicReplicaSet controller reconciles its state.
 So while our BasicDeployment does need additional logic to incorporate the usage of BasicReplicaSet resources, most of the newly introduced logic is nicely incorporated into the BasicReplicaSet controller.
So while our BasicDeployment does need additional logic to incorporate the usage of BasicReplicaSet resources, most of the newly introduced logic is nicely incorporated into the BasicReplicaSet controller.
Lessions learned
Use when
- There are parent-child semantic relations between the objects you control.
Pros
- Proved effectiveness, it is in Kubernetes core.
- Support sophisticated variants, e.g. history of changes, rollbacks.
Cons
- Not trivial to debug: Why is the resource not progressing?
- Not trivial to evolve: Change in a resource might impact more than one controller.
API Contracts
When we are designing our Kubernetes Extension, we can more or less plan ahead and break down our tasks into different Custom Resources and their corresponding controllers. We can put together complex system of resources that rely on each other.
What happens when we want to extend an already vast ecosystem of resources or if we want third-parties to be able to do this? Like we’ve seen previously, with parent-child relationships, a lot of functionality can be offloaded to other resources and their controllers, but we must still incorporate handling those resources in our parent controller. When we do this, we interact with the resource itself. Knowing the exact child resource might not sound like too much of a burden, but it is still rather intimate knowledge, especially when you might want to generalize the logic that handles it.
Let’s say we want to build a different implementation of BasicReplicaSet or rather, a new resource that fulfills the same duties, but it might do it in a different way. Using this resource instead of BasicReplicaSet in our BasicDeployment reconciliation would not be entirely trivial, as our code directly relies on the BasicReplicaSet resource. We would want something that’s basically a “pluggable” resource, fulfilling every need BasicDeployment has towards it with little to no change to existing controllers.
These were precisely the kind of problems that the SIG Cluster Lifecycle faced when they were developing the Cluster API project.
API Contracts try to solve these problems by introducing the concept of (as the name implies) a contract. When adhering to this contract, the resource is expected to have a set of well-known fields.
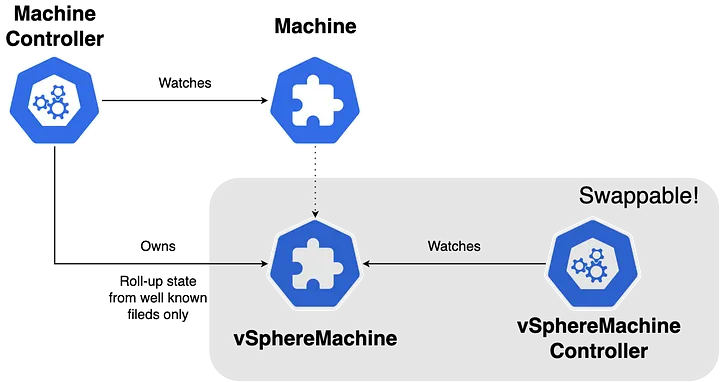
Returning to our Machine example, we are trying to create a Machine . This machine can be created on a lot of different infrastructures. For us, the only relevant information from the Machine resource point of view is whether or not said machine is ready. To actually create it and get it to a ready state, we could make a custom resource and a corresponding controller that handle this workload, but since there are multiple ways to achieve this, we would need to create multiple custom resources and controllers. Using API Contracts, we can develop a controller for the Machine that handles these resources through contracts, making them completely swappable.
The full code for our example operator is available on GitHub. If you want to dive deeper into the Cluster API’s API Contract implementation, be sure to check out the project’s repository.