
· 10 min read
AWS Bedrock Overview
Amazon Bedrock provides access to 100+ AI models via a single API, with enterprise-grade security and flexible, token-based pricing.
One of the most important questions regarding the AI revolution at the enterprise level is not which model is best, but how to operate them securely, at scale, and at predictable costs. Amazon Web Services’ answer to this is Amazon Bedrock - a fully managed platform that provides access to the world’s leading AI models through a unified API.
What is Amazon Bedrock?
Amazon Bedrock is a fully managed generative AI service that enables developers and businesses to access foundation models from various providers within their own AWS infrastructure - without having to operate their own servers or train models.
The platform is all about simplicity and flexibility. The various models are unified behind a single, consistent API, which means we can switch from one model to another by changing just a single parameter. This allows us to use different models for different tasks and compare them under real-world conditions.
Bedrock does more than just provide access to models. The platform integrates AWS’s entire security and compliance framework - IAM access management, VPC isolation, CloudTrail logging, and encryption - so that AI workflows running on it inherit the enterprise-grade protection that AWS customers have come to expect for years.
In addition, Bedrock offers built-in tools for RAG (Retrieval-Augmented Generation) based knowledge bases, AI agent development, moderation (guardrails), model fine-tuning, and batch inference. Through the Bedrock Marketplace, more than 100 base models from over 15 different providers are available in a single catalog, including smaller, specialized models.
How does Bedrock’s pricing work?
Amazon Bedrock operates on a pay-as-you-go basis, which means there are no subscription fees, no minimum commitment, and no need to reserve capacity in advance. Billing is entirely token-based, meaning the final cost is calculated based on the number of tokens in the input (prompt) and the output (the model’s response). For English text, one token is roughly equivalent to 4 characters or 0.75 words. Service prices are quoted per 1 million tokens, and it is important to note that the input is always cheaper than the output: the model’s response typically costs 3–5 times as much as the input prompt.
| Model | Price per 1M input tokens | Price per 1M output tokens |
|---|---|---|
| Amazon Nova Micro | $0,046 / 1M token | $0,184 / 1M token |
| Claude Opus 4.8 | $5,00 / 1M token | $25,00 / 1M token |
There can be a huge difference in pricing between models: Amazon Nova Micro is available for just $0.046 per million input tokens in the European (eu-central-1) region, while Claude Opus 4.8 charges $5.00 for the same number of input tokens in the same region - a difference of more than 100 times. The difference is even more striking on the output side: Nova Micro charges $0.184 per million tokens, while Claude Opus 4.8 charges $25.00 per million tokens - a 136-fold difference. That is why choosing the right model is one of the most impactful decisions in Bedrock workflows - a poor choice can increase the cost by as much as a hundredfold for the same task.
Service tiers: Standard, Priority, Flex, Reserved
In addition to token prices, Bedrock allows us to classify individual requests into different service tiers, which affect the balance between price and performance. There are currently four tiers:
Standard – This is the default tier, available for all base models. It delivers reliable performance for everyday AI tasks, such as chatbots, summarization, or code generation. There are no extra fees and no minimum commitment.
Priority – This tier comes with a 75% surcharge compared to the Standard tier, but in return, requests are given priority in the processing queue, even during peak periods. With most models that support the Priority tier, you can achieve up to 25% better output token-per-second latency compared to the Standard tier. Can be enabled without prior reservation: simply set the serviceTier parameter to priority in the API call. This is recommended when the application runs real-time, user-facing workflows where any delay would result in a noticeable degradation of the user experience.
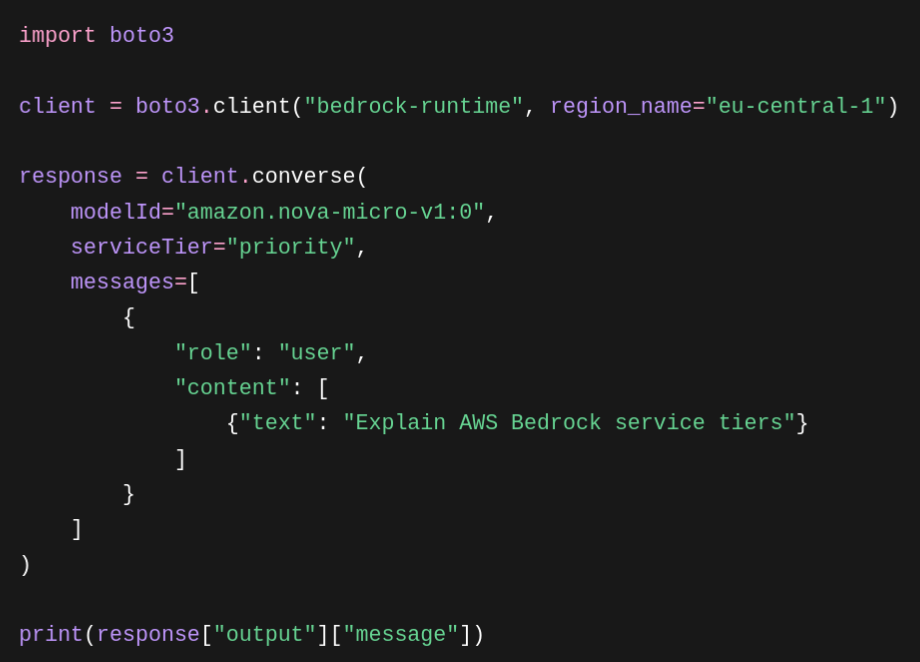
Example of using Service Tier in an AWS Bedrock API call
Flex – Offers a 50% discount on the Standard price; in exchange, requests have longer wait times and lower processing priority during peak hours. Ideal for non-interactive, time-critical workloads: model evaluation, content tagging, summarization of long documents, multi-step agentic workflows. It can also be easily activated via an API parameter.
Reserved – This tier is designed for companies that require predictable, high-volume, and guaranteed capacity. With the Reserved tier, we reserve a predetermined capacity of tokens per minute for a period of 1 or 3 months and pay a fixed fee of 1,000 tokens per minute, regardless of actual usage. If demand exceeds the reserved capacity, the system automatically switches to the Standard tier. This tier targets a 99.5% SLA (Service Level Agreement) and can be requested in collaboration with the AWS account team.
Let’s look at an illustrative example
Suppose we operate an enterprise content processing system that generates 10 million output tokens per month using the Claude Haiku 4.5 model.
| Service Tier | Price / 1M output token | Monthly cost |
|---|---|---|
| Standard | $5,00 | $50,00 |
| Flex (50% discount) | $2,50 | $25,00 |
| Priority (75% surcharge) | $8,75 | $87,50 |
If your system is asynchronous and performs nightly batch processing, and an immediate response isn’t required, the Flex tier can cut your bill in half. However, if your application is a real-time customer service chatbot where every second counts, it may be worth paying the premium for the Priority tier.
It’s also worth mentioning the Batch Inference option: if you send prompts packaged in a JSONL file via Amazon S3 and a 24-hour turnaround time is acceptable, you’ll also receive a 50% discount - this corresponds to the Flex tier pricing, but operates in a fully asynchronous manner.
Model Showcase
One of Bedrock’s greatest strengths is the diversity of its models. As of June 2026, approximately 113 models from 18 different providers are available on the platform across 30 AWS regions. The main providers and model families are:
Amazon Nova és Titan
Amazon’s in-house models are primarily optimized for use cases that are deeply integrated into the AWS ecosystem. The Nova series (Micro, Lite, Pro, Premier, Omni, Sonic) covers a wide range: the smallest Micro model is extremely affordable and fast for simple tasks, while the Premier and Omni models are suitable for complex, multi-step agentic AI workflows and multimodal tasks. The biggest advantage of the Amazon models is that they run as native, first-party AWS services - data never leaves the AWS infrastructure, and no external data processing agreement is required. The Titan series is primarily designed for embedding generation and text-based tasks.
Choose this option if your application is deeply integrated with AWS (DynamoDB, S3, Lambda) and data sovereignty or compliance is a priority. Amazon Nova instances offer excellent value for money with a low entry barrier.
Anthropic – Claude
Claude models excel at complex reasoning, following detailed instructions, safe behavior, and code generation. The latest versions available on Bedrock (Claude Sonnet 4.6, Claude Opus 4.7) deliver cutting-edge performance. Claude’s pricing on Bedrock matches Anthropic’s direct API rates - there is no extra surcharge.
Choose this option when you need to analyze long documents, process legal or financial texts, generate complex code, or when the reliable and secure operation of the model is of paramount importance.
Meta - Llama
Meta’s Llama model family (ranging from Llama 2 to the Llama 4 Scout and Maverick variants) consists of “pre-trained” models that allow for fine-tuning and customization to meet specific needs. The downside is that Llama models running on Bedrock can cost 30–200% more than those from dedicated inference providers - AWS charges a premium for its managed service to cover infrastructure and compliance tools.
Choose this option if you need the “open-weight” (pre-trained) and highly tunable nature of Llama models, while your application runs in an AWS environment and compliance requirements necessitate operation within the unified AWS ecosystem.
Mistral AI
Mistral models offer efficient, high-performance inference even in smaller sizes. They are particularly well-suited for applications that must comply with European data protection requirements (GDPR), as they can be run in AWS regions within the EU.
Choose this option when you need to handle tasks of moderate complexity, require fast response times, and seek cost-effective operation - especially if you must also comply with European data retention requirements.
Cohere
Cohere’s models are primarily designed for enterprise search and RAG applications. Command R+ performs particularly well in retrieval-augmented generation pipelines, where relevant information needs to be extracted from large volumes of documents.
Choose this option for document searches based on internal knowledge bases or RAG-based systems, where accurately retrieving relevant sources and ensuring citability are critical to finding the correct answer.
OpenAI
In the spring of 2026, Amazon and OpenAI expanded their partnership: the GPT-5.5 and GPT-5.4 models, as well as the Codex coding agent, became generally available on Bedrock. The models run on Bedrock’s next-generation inference engine and are available at the same pricing as OpenAI’s direct APIs, with no additional fees. They are integrated with AWS authentication and Bedrock’s security infrastructure.
Choose this option if you need OpenAI’s top-tier models, but your application runs entirely within the AWS ecosystem, and unified security, logging, and IAM-based access management are critical.
Stability AI, Luma AI, TwelveLabs and others
Bedrock offers more than just text models. Stability AI provides models specialized in image generation (Stable Diffusion), Luma AI in video generation, and TwelveLabs in video understanding and analysis. The Qwen (Alibaba), MiniMax, DeepSeek, and NVIDIA Nemotron models are also available, primarily for specialized research, coding, and efficiency use cases. Some models are only available in certain regions.
How do we choose the right model?
When selecting the right model, it’s worth considering three factors together: the type of task, cost, and compliance requirements. For complex reasoning and code generation, the Claude or GPT-5.x models are the most powerful, while for simple, high-volume tasks, Amazon Nova Micro or Lite offer sufficient performance at a fraction of the cost. For RAG-based search, Cohere Command R+ is the obvious choice; for image generation, Stability AI; and for a fine-tunable “open-weight” (pre-trained) solution, Meta Llama is the obvious choice. If data cannot leave the AWS infrastructure, Amazon Nova models are the most secure option - and for third-party models, Bedrock’s security layer (VPC, IAM, encryption) ensures that data does not end up on the open internet.
It’s best to strike a balance between cost and quality gradually: start by experimenting with smaller, less expensive models, and only move up the scale if the quality isn’t satisfactory. Bedrock’s Intelligent Prompt Routing feature also helps with this, automatically routing requests between a more expensive and a cheaper model based on the complexity of the prompt - resulting in cost savings of up to 30%.
However, Bedrock’s true strength lies in the fact that all of this is powered by a single API. You don’t have to commit to a single model: you can experiment, run A/B tests, and continuously optimize - even using different models for different tasks within the same application.
Sources
Are you interested in this topic? Do you have any questions about the article? Book a free consultation and let’s see how the Code Factory team can help you, or take a look at our services!