
· 5 min read
RAG olcsón: AWS S3 Vector Store
AWS S3 Vectors segítségével a lehető legegyszerűbb és legolcsóbb módon építettünk RAG rendszert, amely célzott tudással ruház fel egy LLM-et.

Bevezetés
Ez a projekt úgy indult, hogy egy tesztelési folyamat során szükségünk volt egy egyszerű RAG (Retrieval-Augmented Generation) rendszerre AWS-en. Korábban már többször foglalkoztunk RAG-gal, és első körben az OpenSearch-ben gondolkodtunk. Mivel ez az AWS saját managed vector search szolgáltatása, ez kézenfekvő megoldásnak tűnt, de felmerült bennünk a kérdés, hogy van-e ennél egyszerűbb vagy olcsóbb alternatíva. Úgy döntöttünk, hogy ez jó alkalom lesz kipróbálni az AWS S3 új Vectors szolgáltatását, ami gyakorlatilag natív vektortárolást hoz közvetlenül az S3-ba.
AWS S3 Vector Store
Az AWS S3 Vectors (vagy AWS S3 Vector Store) egy olyan natív vektortárolási megoldás az S3-on belül, ami kifejezetten embeddingek tárolására és lekérdezésére lett kialakítva.
Mit tud az S3 Vector Store?
- embedding vektorok tárolása és indexelése S3-ban,
- hasonlóság alapú keresés (RAG use case-re optimalizálva),
- nulla infrastruktúra menedzsment,
- alacsony költségek.
A klasszikus vektoradatbázisok ugyanakkor általában erősebbek és rugalmasabbak összetett keresési igények, komplex lekérdezések és nagy terhelés esetén.
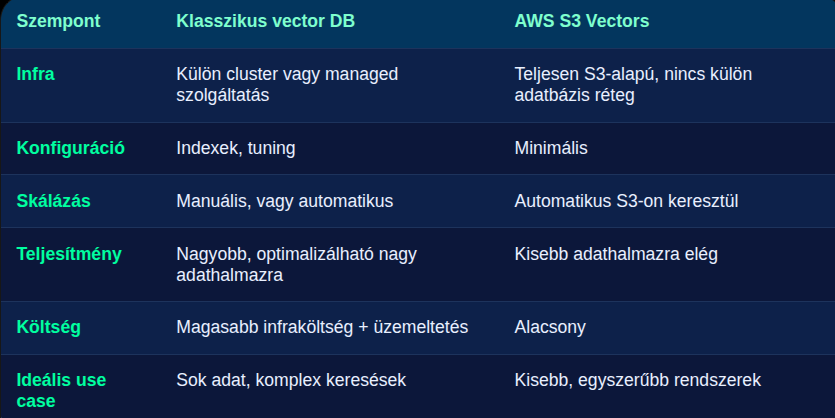
Hogyan építettük fel a projektet?
A projekt célja az volt, hogy egy viszonylag kicsi adathalmazt adjunk az LLM-nek, amiből meg tud válaszolni specifikus állatorvosi kérdéseket. Az infrastruktúrát, amire a rendszer üzemeltetéséhez volt szükség, igyekeztünk minél egyszerűbben összerakni.
A működéshez szükség van egy Vector Storage bucket-re, illetve egy sima Object Storage bucket-re is a nyers fájlok tárolására. A feldolgozási folyamatot nagyon egyszerűen ki lehet alakítani, elég kisebb Python Lambda-kat használni egy Step Functions flow-ban. Az alapvetően szükséges részeken felül mi egy külön Lambda-t is beleépítettünk a projektbe, amivel a folyamat végén a teszt promptokat lehetett beküldeni.
A teljes infrastruktúra így nézett ki:
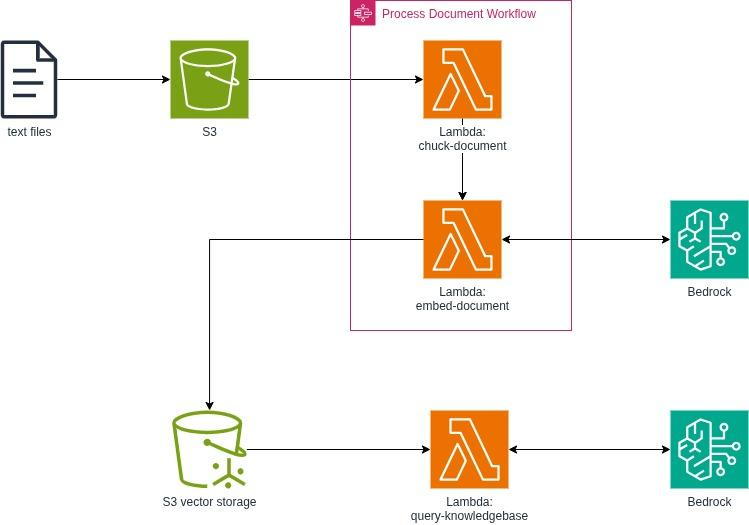
Az adatok feldolgozása
Első lépésként kerestünk néhány tanulmányt nagyon specifikus állatorvosi témákkal. Ezeket feltöltöttük S3-ba. Ezután elindítottuk a Step Function-t, ami a feltöltött fájl nevét kapta bemenetként és két lépést futtatott:
- Chuck Document: beolvassa a cikket a
raw_data/{path}/article.txt-ből, 1000 karakteres darabokra vágja 200 karakteres átfedéssel, és kiírja aprocessed/{path}/article_chunks.json-be. A chunk méretét és az overlap mértékét állíthatóan hagytuk, hiszen ezek finomhangolása hatással van a visszakeresés pontosságára. A kisebb chunkok pontosabb visszakeresést adhatnak, viszont könnyebben elveszhet a kontextus, míg a nagyobb chunkok több kontextust őriznek meg, de zajosabb találatokat eredményezhetnek. Az átfedés abban segít, hogy a fontos információk ne tudjanak elveszni a chunk határainál, viszont minél nagyobbra állítjuk, annál jobban növeli a tárolási és feldolgozási költségeket (még ha ennek a projekt méretén nincs is igazán jelentősége). - Embed Document: beolvassa a chuck-okat, embedding-eket generál és eltárolja a vektorokat az S3 Vectors indexekben a szöveggel mint metaadat. Ehhez az Amazon Titan Text Embeddings V2 modellt használtuk, ami egy AWS által fejlesztett, kifejezetten embedding use case-ekre optimalizált és viszonylag költséghatékony foundation model.
A tesztelő Lambda
A teszt lambdát úgy állítottuk össze, hogy egy manuális bemenetet várjon ezekkel a mezőkkel:
{
"question": "Minek a rövidítése az ADCPC??",
"use_rag": false
}Azt, hogy a lambda melyik Bedrock modellt használja, szintén egy külső változóban adtuk meg, hogy később könnyen tudjuk állítani. A prompt is végtelenül egyszerű volt, a feltett kérdésből és use_rag=true esetén a vector store-ból lekért kontextusból állt össze.
def retrieve_context(s3vectors, bedrock, question: str, top_k: int) -> tuple[str | None, list[str]]:
embedding = get_embedding(bedrock, question)
results = query_vectors(s3vectors, embedding, top_k)
chunks = []
sources = []
for r in results:
meta = r.get("metadata", {})
text = meta.get("text", "")
if text:
chunks.append(text)
sources.append(r["key"])
context = "\n\n---\n\n".join(chunks) if chunks else None
return context, sources
def build_prompt(question: str, context: str | None) -> str:
if context:
return f"""Use the following context to answer the question. If the context doesn't contain relevant information, say so.
Context:
{context}
Question: {question}"""
return questionA prompt-on önmagában is rengeteget lehetne itt még optimalizálni, például szabályozhattuk volna jobban, hogy a modell kizárólag a retrieved context alapján válaszoljon, megadhattunk volna egy explicit válaszformátumot vagy kérhettünk volna source citationt minden válasz végére.
Viszont még ezzel az egysoros, kifejezetten egyszerű prompttal is beleütköztünk egy említésre méltó „hibába”. Az Nova Lite modell, amit a teszteléshez használtunk, mindenféle kontextus nélkül is meglepően jól válaszolt az állatorvosi kérdésekre. Ehhez azért az is hozzátartozik, hogy nem rendelkeztünk jelentős szaktudással a témában, így szinte biztos, hogy néhány hibát mi sem vettünk észre. Ugyanakkor a modell szemmel láthatóan nem akadt fenn sem latin szakkifejezéseken, sem gyógyszerneveken, még akkor sem, amikor magyar és angol nyelvű kérdésekkel vegyesen próbáltuk terhelni.
Emiatt végül specifikusabb módszert kellett találnunk a vector store és a retrieval pipeline tesztelésére. Keresnünk kellett egy konkrét állatorvosi témájú tanulmányt, amelyre már úgy lehetett rákérdezni, hogy a RAG hozzáadott értéke valóban látható legyen. Egy teszt során például több mint egy tucat tünet alapján az LLM sikeresen azonosított egy betegséget, amely RAG nélkül még a lehetséges találatai között sem szerepelt, és még a szakmai rövidítéseken sem akadt fenn a szeme.
Mennyibe kerül ez így
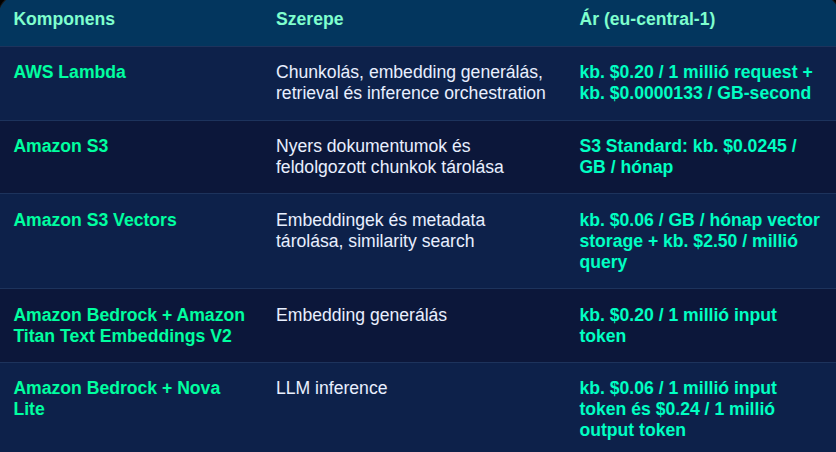
A teljes infra összköltsége nagyon alacsony, és mivel minden komponens serverless árazást használ, így nincs is fix infrastruktúra költség, csak a használat után fizetünk. Az egész tesztelési folyamat alatt összességében nem sikerült az egy dolláros határt elérnünk.
Tanulság
Bőven lehetne még mit fejleszteni ezen a projekten. A chunkolási stratégia jelenleg elég naiv, fix chunk mérettel és overlap-pel dolgoztunk, és az embedding/query modellekkel sem kísérleteztünk még túl sokat, a prompting stratégia pedig további finomhangolásra szorul. Az viszont egyértelművé vált, hogy az S3 Vectors meglepően jól működik RAG backendként. Kisebb projektekhez és POC-okhoz, ahol nincs nagy mennyiségű adat, különösen jó választás lehet, főleg mert jóval olcsóbb, mint más, hasonló alternatívák.
Kérdésed van? Írj nekünk, és mi segítünk megtalálni a számodra optimális megoldásokat.