
· 8 min read
AWS Bedrock ismeretterjesztő
Az Amazon Bedrock egységes API-n keresztül kínál hozzáférést 100+ AI-modellhez, vállalati biztonsággal és rugalmas, token alapú árazással.
Az AI-forradalom egyik legfontosabb kérdése vállalati szinten nem az, hogy melyik modell a legjobb, hanem az, hogy hogyan lehet ezeket biztonságosan, skálázhatóan és kiszámítható költségek mellett üzemeltetni. Az Amazon Web Services erre adott válasza az Amazon Bedrock – egy teljesen menedzselt platform, amely egységes API-n keresztül teszi elérhetővé a világ vezető AI-modelljeit.
Mi az az Amazon Bedrock?
Az Amazon Bedrock egy fully managed (teljesen felügyelt) generatív AI-szolgáltatás, amely lehetővé teszi, hogy a fejlesztők és vállalatok a saját AWS-infrastruktúrájukon belül érjék el a különböző szolgáltatók alapmodelljeit (foundation models) – anélkül, hogy saját szervereket kellene üzemeltetniük, vagy modelleket kellene betanítaniuk.
A platform lényege az egyszerűség és a rugalmasság. Egyetlen, egységes API mögé sorakoznak fel a különböző modellek, ami azt jelenti, hogy akár egyetlen paraméter módosításával válthatunk egyik modellről a másikra. Ez lehetővé teszi, hogy különböző feladatokhoz különböző modelleket használjunk, és azokat valós körülmények között hasonlítsuk össze.
A Bedrock nem pusztán modell-hozzáférést biztosít. A platform integrálja az AWS teljes biztonsági és megfelelőségi rendszerét – IAM jogosultságkezelés, VPC izoláció, CloudTrail naplózás, és titkosítás – így az ott futtatott AI munkafolyamatok öröklik azt a vállalati szintű védelmet, amelyet az AWS-ügyfelek már évek óta elvárnak.
Emellett a Bedrock beépített eszközöket kínál RAG (Retrieval-Augmented Generation) alapú tudásbázisokhoz, AI-ügynökök (agents) felépítéséhez, moderációhoz (guardrails), modell-finomhangoláshoz (fine-tuning), valamint tömeges feldolgozáshoz (batch inference) is. A Bedrock Marketplace révén ezen felül több mint 100 alapmodell 15+ különböző szolgáltatótól érhető el egyetlen katalógusból, köztük kisebb, specializált modellek is.
Hogyan működik a Bedrock árazása?
Az Amazon Bedrock alapvetően pay-as-you-go elven működik, ami azt jelenti, hogy nincs előfizetési díj, nincs minimális elköteleződés, és előzetes kapacitásfoglalásra sincs szükség. A számlázás teljes mértékben token alapú, vagyis a végső költség az elküldött input (prompt) és a visszakapott output (a modell válasza) tokenjeinek száma alapján kerül kiszámításra. Az angol szövegek esetében egy token nagyjából 4 karakternek vagy 0,75 szónak felel meg. A szolgáltatás árait 1 millió tokenre vetítve adják meg, és fontos tudni, hogy az input mindig olcsóbb, mint az output: a modell válasza jellemzően 3–5-ször annyiba kerül, mint a bemeneti prompt.
| Model | Ár / 1M bemenő token | Ár / 1M kimenő token |
|---|---|---|
| Amazon Nova Micro | $0,046 / 1M token | $0,184 / 1M token |
| Claude Opus 4.8 | $5,00 / 1M token | $25,00 / 1M token |
A modellek árazása között óriási különbség lehet: az Amazon Nova Micro mindössze 0,046 USD / 1 millió input tokenért érhető el az európai (eu-central-1) régióban, míg a Claude Opus 4.8 ugyanitt 5,00 USD-t számít fel ugyanannyi input tokenért – ez több mint 100-szoros különbség. Output oldalon még szembetűnőbb az eltérés: Nova Micro esetén 0,184 USD, Claude Opus 4.8-nál 25,00 USD jár 1 millió tokenenként, azaz 136-szoros szorzóval. Éppen ezért a megfelelő modell kiválasztása az egyik legnagyobb hatású döntés a Bedrock-os munkafolyamatoknál – egy rossz választás ugyanolyan feladaton akár százszorosára növelheti a számlát.
Service tier-ek: Standard, Priority, Flex, Reserved
A tokenárakon túl a Bedrock lehetővé teszi, hogy az egyes kéréseket különböző service tier-ekbe soroljuk be, amelyek az ár és a teljesítmény közötti egyensúlyt befolyásolják. Jelenleg négy tier létezik:
Standard – Ez az alapértelmezett szint, minden alapmodellnél elérhető. Megbízható teljesítményt nyújt hétköznapi AI-feladatokhoz, például chatbotokhoz, összefoglaláshoz vagy kódgeneráláshoz. Nincs extra felár, nincs minimális elköteleződés.
Priority – A Standard szinthez képest 75%-os felárral jár, cserébe viszont a kérések prioritást élveznek a feldolgozási sorban a csúcsidőszakokban is. A legtöbb Priority tier-t támogató modellnél akár 25%-kal jobb kimeneti token/másodperc latenciát is el lehet érni a Standard szinthez képest. Előzetes foglalás nélkül aktiválható: elegendő az API-hívásban a serviceTier paramétert priority értékre állítani. Akkor érdemes használni, ha az alkalmazás valós idejű, felhasználóval szemben álló munkafolyamatokat futtat, ahol a késés érzékelhető felhasználói élménybeli romlást okozna.
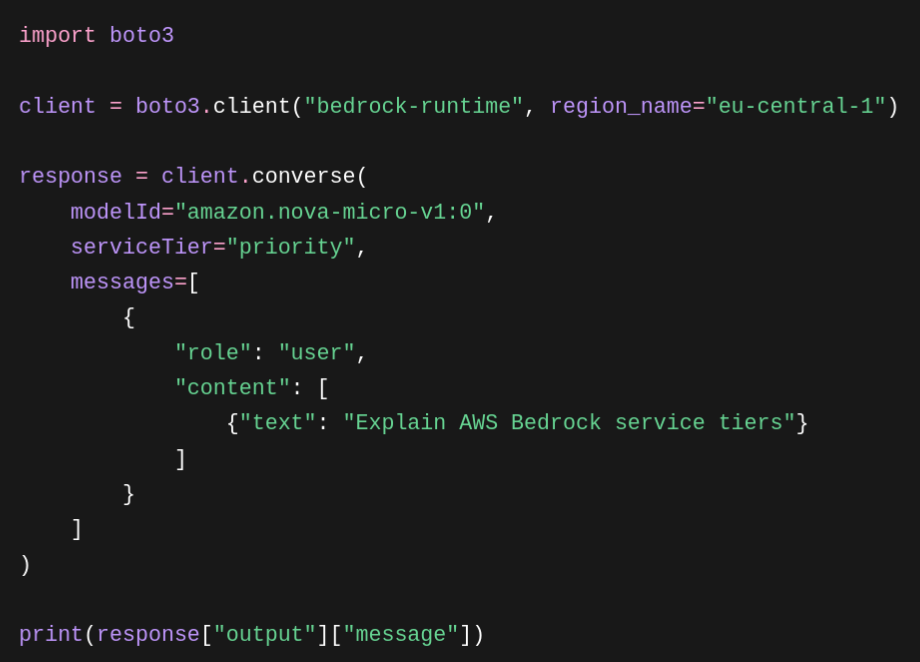
Példa a Service Tier használatára AWS Bedrock API hívásban
Flex – A Standard ár 50%-os kedvezményét kínálja, cserébe a kérések magasabb várakozási idővel és alacsonyabb feldolgozási prioritással rendelkeznek csúcsidőben. Nem interaktív, időkritikus munkaterhelésekhez ideális: modellértékelés, tartalomcímkézés, hosszú dokumentumok összefoglalása, többlépéses agentic workflow-k. Szintén egyszerűen aktiválható az API-paraméteren keresztül.
Reserved – Ez a tier azoknak a vállalatoknak szól, akiknek kiszámítható, nagy volumenű és garantált kapacitásra van szükségük. A Reserved tier esetén előre meghatározott token/perces kapacitást foglalunk le 1 vagy 3 hónapos időszakra, és fix díjat fizetünk 1000 token/perc egységenként, függetlenül a tényleges felhasználástól. Amennyiben a szükséglet meghaladja a lefoglalt kapacitást, a rendszer automatikusan a Standard tier-re vált át. A tier 99,5%-os SLA-t (Service Level Agreement) céloz, és az AWS account teammel együttműködve igényelhető.
Nézzünk egy szemléltető példát
Tegyük fel, hogy egy vállalati tartalom-feldolgozó rendszert üzemeltetünk, amely havonta 10 millió output tokent generál a Claude Haiku 4.5 modell segítségével.
| Service Tier | Ár / 1M output token | Ár / Havi költség |
|---|---|---|
| Standard | $5,00 | $50,00 |
| Flex (50% kedvezmény) | $2,50 | $25,00 |
| Priority (75% felár) | $8,75 | $87,50 |
Ha a rendszer aszinkron, éjszakai kötegelt feldolgozást végez, és nincs szükség azonnali válaszra, a Flex tier-rel a felére csökkenthetjük a számlát. Ha viszont az alkalmazás valós idejű ügyfélszolgálati chatbot, ahol másodpercek számítanak, a Priority tier prémiumát érdemes lehet megfizetni.
Érdemes megemlíteni a Batch Inference lehetőséget is: ha egy JSONL fájlba csomagolva, Amazon S3-on keresztül küldjük el a promptokat, és a 24 órás átfutási idő elfogadható, szintén 50%-os kedvezményt kapunk – ez megfelel a Flex tier árszintjének, de teljesen aszinkron módon működik.
Modellek bemutatása
A Bedrock egyik legnagyobb erőssége a modellek sokfélesége. 2026 júniusában a platformon 18 különböző szolgáltató mintegy 113 modellje érhető el 30 AWS-régióban. A főbb providerek és modellcsaládok:
Amazon Nova és Titan
Az Amazon saját fejlesztésű modelljei elsősorban az AWS ökoszisztémába mélyen integrált use case-ekre optimalizáltak. A Nova sorozat (Micro, Lite, Pro, Premier, Omni, Sonic) széles skálán mozog: a legkisebb Micro modell rendkívül olcsó és gyors egyszerű feladatokhoz, a Premier és Omni viszont összetett többlépéses agentic AI-munkafolyamatokra és multimodális feladatokra alkalmas. Az Amazon modellek legnagyobb előnye, hogy natív első féltől származó AWS-szolgáltatásként futnak – az adat nem hagyja el az AWS-infrastruktúrát, és nincs szükség külső adat-feldolgozási megállapodásra. A Titan sorozat főleg embedding-generálásra és szöveges feladatokra készült.
Akkor válasszuk, ha az alkalmazás mélyen integrált az AWS-el (DynamoDB, S3, Lambda) és fontos az adatszuverenitás vagy a compliance. Az Amazon Nova modellek alacsony belépési küszöb mellett kínálnak kiváló ár-érték arányt.
Anthropic – Claude
A Claude-modellek az összetett érvelés, a részletes utasítások követése, a biztonságos viselkedés és a kódgenerálás terén kiemelkedőek. A Bedrockon elérhető legújabb verziók (Claude Sonnet 4.6, Claude Opus 4.7) egészen a csúcs-frontier teljesítményig terjednek. A Claude árazása a Bedrockon megfelel az Anthropic közvetlen API-árainak – nincs extra felár.
Akkor válasszuk, ha hosszú kontextusú dokumentumelemzésre, jogi vagy pénzügyi szövegek feldolgozására, összetett kódgenerálásra van szükség, vagy amikor kiemelten fontos a modell megbízható és biztonságos működése.
Meta - Llama
A Meta Llama modellcsaládja (Llama 2-tól egészen a Llama 4 Scout és Maverick változatokig) “nyílt súlyú” (pre-trained) modellekből épül fel, amelyek lehetővé teszik a finomhangolást és a saját igényekre való testreszabást. Hátránya, hogy a Bedrockon futtatott Llama-modellek 30–200%-kal többe kerülhetnek, mint dedikált inference-szolgáltatóknál – az AWS managed-service prémiumot felszámít az infrastruktúráért és a compliance-eszközökért.
Akkor válasszuk, ha szükség van a Llama modellek “nyílt súlyú” (pre-trained) és jól finomhangolható jellegére, miközben az alkalmazás AWS környezetben fut, és a compliance követelmények az egységes AWS-ökoszisztémán belüli működést indokolják.
Mistral AI
A Mistral modellek hatékony, magas teljesítményű inferenciát kínálnak kisebb méretben is. Különösen alkalmasak európai adatvédelmi követelményeket (GDPR) szem előtt tartó alkalmazásokhoz, mivel az EU-s AWS-régiókban is futtathatóak.
Akkor válasszuk, ha közepes bonyolultságú feladatokra, gyors válaszidőre és költséghatékony működésre van szükség, különösen akkor, ha európai, az adatok helyben tartására vonatkozó követelményeknek is meg kell felelni.
Cohere
A Cohere modellei elsősorban vállalati keresési és RAG-alkalmazásokra specializálódtak. A Command R+ különösen jó retrieval-augmented generation pipeline-okban, ahol nagy mennyiségű dokumentumból kell releváns információt kinyerni.
Akkor válasszuk, ha belső tudásbázisokra épülő dokumentumkeresésről, vagy RAG-alapú rendszerekről van szó, ahol a helyes válaszhoz kritikus a releváns források pontos visszakeresése és a hivatkozhatóság biztosítása.
OpenAI
2026 tavaszán az Amazon és az OpenAI kibővítette partnerségét: a GPT-5.5 és GPT-5.4 modellek, valamint a Codex coding agent általánosan elérhetővé váltak a Bedrockon. A modellek a Bedrock következő generációs inference engine-jén futnak, és az OpenAI közvetlen API-áraival megegyező díjszabás mellett, extra felár nélkül érhetőek el. Az AWS-hitelesítéssel és a Bedrock biztonsági infrastruktúrájával integráltan működnek.
Akkor válasszuk, ha az OpenAI csúcsmodelljeire van szükség, de az alkalmazás teljes mértékben az AWS-ökoszisztémában fut, és az egységes biztonsági, naplózási és IAM-alapú hozzáférés-kezelés kulcsfontosságú.
Stability AI, Luma AI, TwelveLabs és egyebek
A Bedrock nem csak szöveges modelleket kínál. A Stability AI képgenerálásra (Stable Diffusion), a Luma AI videógenerálásra, a TwelveLabs videómegértésre és -elemzésre specializált modelleket nyújt. A Qwen (Alibaba), MiniMax, DeepSeek és NVIDIA Nemotron modellek szintén elérhetőek, elsősorban speciális kutatási, coding- és hatékonysági use case-ekre. Néhány modell csak bizonyos régiókban elérhető.
Hogyan válasszuk ki a megfelelő modellt?
A megfelelő modell kiválasztásakor három szempontot érdemes együtt mérlegelni: a feladat típusát, a költséget, és a compliance-követelményeket. Összetett érveléshez és kódgeneráláshoz a Claude vagy a GPT-5.x modellek a legerősebbek, egyszerű, nagy volumenű feladatokhoz viszont az Amazon Nova Micro vagy Lite töredék áron nyújt elegendő teljesítményt. RAG-alapú kereséshez a Cohere Command R+, képgeneráláshoz a Stability AI, finomhangolható “nyílt súlyú” (pre-trained) megoldáshoz pedig a Meta Llama a kézenfekvő választás. Ha az adat nem hagyhatja el az AWS-infrastruktúrát, az Amazon Nova-modellek a legbiztonságosabb opció – harmadik fél modelljeinél pedig a Bedrock biztonsági rétege (VPC, IAM, titkosítás) gondoskodik arról, hogy az adatok ne kerüljenek ki a nyílt internetre.
A költség és a minőség közötti egyensúlyt érdemes fokozatosan megtalálni: először a kisebb, olcsóbb modellekkel célszerű kísérletezni, és csak akkor lépni fel a skálán, ha a minőség nem megfelelő. Ebben segít a Bedrock Intelligent Prompt Routing funkciója is, amely automatikusan a prompt komplexitása alapján irányítja a kéréseket egy drágább és egy olcsóbb modell között – akár 30%-os költségmegtakarítást is hozva.
A Bedrock igazi ereje azonban abban rejlik, hogy mindez egyetlen API mögött valósul meg. Nem kell egyetlen modellre fogadni: kísérletezni, A/B tesztelni és folyamatosan optimalizálni lehet, akár feladatonként más-más modellt alkalmazva ugyanazon az alkalmazáson belül.
Források
Kérdésed van? Írj nekünk és mi segítünk abban, hogy megalapozabb döntést tudj hozni egy ilyen helyezetben is!